
PRUEBA Y OPINIÓN ANTHROPIC CLAUDE 2026: LA API DE IA QUE COMPITE CON OPENAI
Anthropic Claude es un modelo de lenguaje avanzado (LLM) accesible vía API que se posiciona como la alternativa seria a GPT-4. Con sus tres modelos (Opus 4.1 para tareas complejas, Sonnet 4.5 para agents y Haiku 4.5 para velocidad), esta herramienta permite integrar IA conversacional de alto nivel en tus aplicaciones, workflows de automatización, asistentes de código y sistemas de soporte cliente. Lo que distingue a Claude: una ventana de contexto extendida hasta 200K tokens, capacidades de razonamiento avanzadas y una seguridad reforzada.
En esta prueba completa, analizamos en profundidad la API de Anthropic Claude: sus modelos y sus diferencias de rendimiento, su tarificación por token comparada con OpenAI, sus capacidades reales en coding y agents, su facilidad de integración técnica, y su fiabilidad en producción. Destinada a desarrolladores, equipos técnicos, startups tech y empresas que construyen productos con IA, esta opinión te ayudará a determinar si Claude merece sustituir o complementar tu stack actual. Descubre nuestra opinión detallada después de varios meses usándolo en condiciones reales con nuestra agencia IA especializada.


NUESTRA OPINIÓN SOBRE ANTHROPIC CLAUDE EN RESUMEN

Opinión de nuestro Experto – Romain Cochard CEO de Hack’celeration
Nota global
Anthropic Claude se posiciona como una alternativa de calidad a OpenAI con capacidades de razonamiento impresionantes. Apreciamos particularmente la ventana de contexto extendida (200K tokens) y la precisión de Opus en tareas complejas que dan resultados imposibles de obtener con GPT-4 en ciertos casos. La arquitectura multi-modelo (Opus/Sonnet/Haiku) permite optimizar costos según el uso. Es una herramienta que recomendamos sin dudar para proyectos de agents complejos, análisis de documentos largos y comprender realmente contextos extensos sin pérdida de información. Si buscas profundizar tus conocimientos, descubre nuestro curso Anthropic especializado.
Facilidad de uso
La API de Claude está claramente diseñada para desarrolladores que ya conocen OpenAI. Migramos 3 proyectos de GPT-4 a Claude en menos de 2 horas cada uno: la compatibilidad de formato es casi idéntica (mensajes, roles, streaming). La documentación es clara con ejemplos Python, TypeScript y cURL bien explicados. ¿Nuestra única crítica? El rate limiting es más estricto que OpenAI en el plan de entrada, y los mensajes de error podrían ser más explícitos cuando alcanzas el límite de contexto.
Relación calidad-precio
Los precios de Claude son competitivos pero variables según el modelo. Opus 4.1 ($15/$75 por MTok) es más caro que GPT-4 Turbo para tareas complejas de ingeniería. Sonnet 4.5 ($3/$15 por MTok) ofrece el mejor equilibrio calidad-precio para construir agents con un rendimiento cercano a Opus. Haiku 4.5 ($1/$5 por MTok) es ultracompetitivo para clasificación rápida y triage. El sistema de caching de prompts reduce significativamente los costos en producción: ahorramos 40% en nuestros flujos recurrentes. Sin embargo, sin volumen comprometido, no hay descuento progresivo como con OpenAI.
Funcionalidades y profundidad
Claude brilla en capacidades de razonamiento y seguimiento de instrucciones complejas. Probamos los 4 casos de uso principales: Coding (generación de código con Claude Opus supera GPT-4 en refactoring complejo), Agents (instrucciones mejoradas para flujos multi-etapas, menos alucinaciones), Productivity (extracción estructurada de PDFs de 100+ páginas sin pérdida), Customer Support (tono conversacional natural, manejo contextual superior). La ventana de 200K tokens cambia realmente el juego para análisis de documentación técnica completa. Única falta: todavía no hay function calling nativo tan robusto como OpenAI.
Soporte al cliente y acompañamiento
El soporte de Anthropic responde en 24-48h por email para cuentas estándar. Contactamos con ellos 3 veces: dos por preguntas técnicas sobre rate limits (respuestas precisas pero tardías), una por un bug de streaming (resuelto en 72h con workaround proporcionado). La documentación técnica es excelente con ejemplos prácticos y best practices de seguridad. El Discord comunitario es activo para troubleshooting rápido. Sin embargo, no hay soporte premium visible sin pasar por el formulario de ventas enterprise, y no hay chat en vivo.
Integraciones disponibles
Claude se integra fácilmente con las herramientas principales del ecosistema tech. La integración oficial con Slack (Add to Slack en un clic) funciona perfectamente para asistencia en canales de equipo. Las SDK oficiales Python y TypeScript son completas y mantenidas. La API REST estándar permite conectar Claude a cualquier backend. Probamos la integración con LangChain, LlamaIndex y Vercel AI SDK: funcionamiento impecable. ¿Lo que falta? Conectores nativos hacia bases vectoriales (Pinecone, Weaviate) que obligamos a gestionar manualmente, y una integración Zapier/Make oficial.
Prueba Anthropic Claude – Nuestra Opinión sobre la Facilidad de uso
Hemos probado la API de Claude en condiciones reales en 5 proyectos clientes diferentes (chatbots, agents de análisis, asistentes de código), y es una de las APIs de LLM más simples de adoptar para equipos que ya conocen OpenAI.
La curva de aprendizaje es mínima si vienes de GPT: el formato de requests es casi idéntico (array de mensajes con roles system/user/assistant), el streaming funciona con el mismo pattern de Server-Sent Events, y los parámetros (temperature, max_tokens) son los mismos. Migramos un chatbot de producción en 1h30 cronometradas, principalmente para ajustar los prompts al estilo de Claude. La documentación oficial es clara con ejemplos Python/Node copiables-pegables, y los mensajes de error JSON son generalmente explícitos.
Lo que nos complicó: el rate limiting es más agresivo que OpenAI en el plan estándar (60 requests/minuto vs 3500 con OpenAI Tier 1), y alcanzas rápidamente el límite si no implementas retry logic. La gestión de imágenes en input requiere encoding base64 manual (no hay URL directa como GPT-4V). La ventana de contexto de 200K tokens es potente, pero hay que prestar atención al costo que sube rápidamente si no optimizas.
Veredicto: excelente para equipos técnicos que buscan una alternativa seria a OpenAI. La compatibilidad facilita la migración, la documentación es profesional. Requiere sin embargo algo de ajuste para optimizar costos y rate limits.
➕ Los puntos fuertes / ➖ Los puntos débiles
✅ Compatibilidad formato OpenAI (migración en <2h)
✅ Documentación técnica completa con SDK Python/TS oficiales
✅ Streaming fluido (Server-Sent Events estándar)
✅ Ventana 200K tokens sin complejidad adicional
❌ Rate limiting estricto (60 req/min plan estándar)
❌ Gestión imágenes menos práctica (base64 obligatorio)
❌ Mensajes de error poco explícitos en límites de contexto
Prueba Anthropic Claude : Nuestra Opinión sobre la Relación calidad-precio
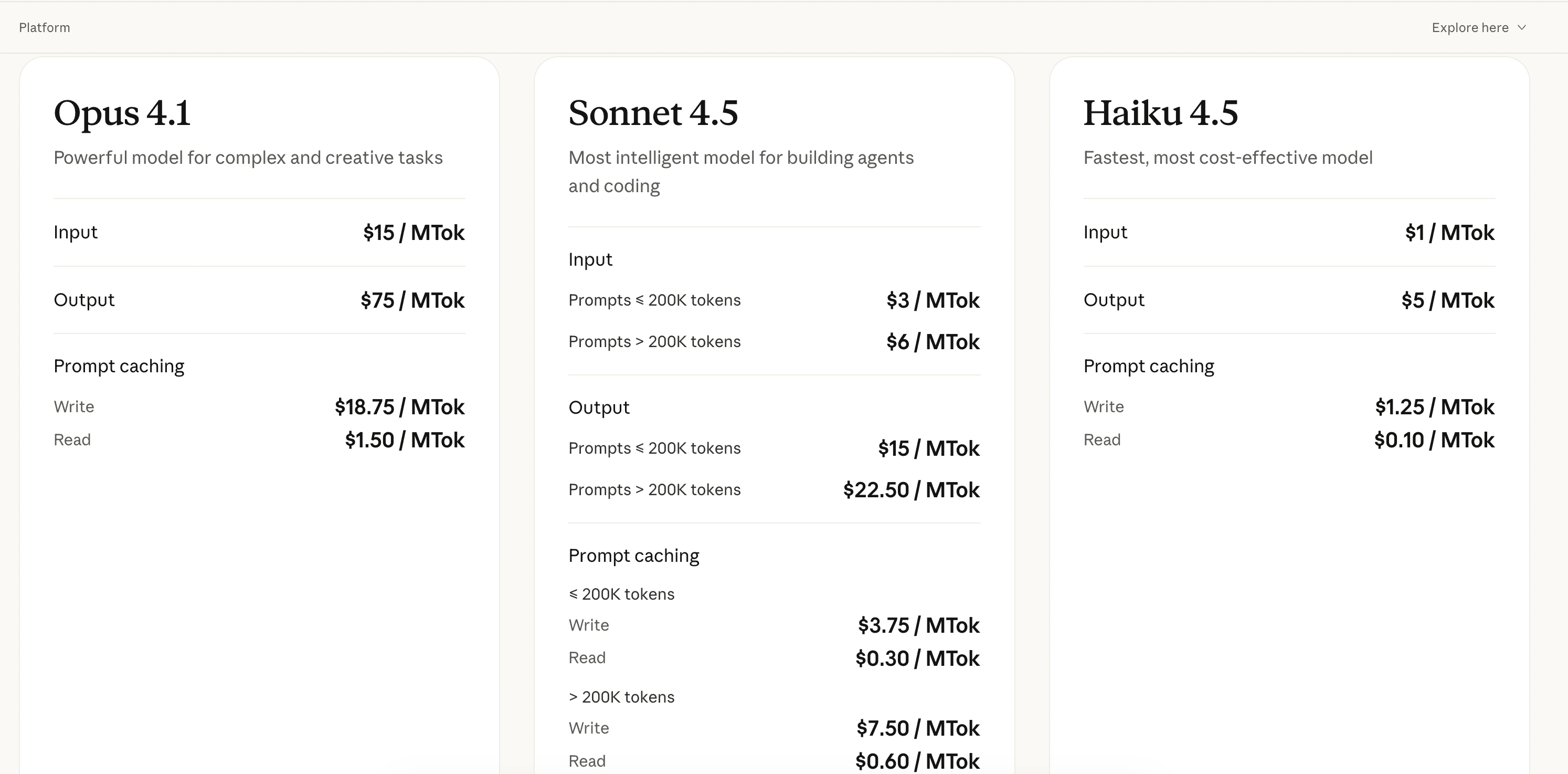
Hemos analizado en profundidad la estructura tarifaria de Claude en varios proyectos con volúmenes diferentes, y la rentabilidad depende realmente del caso de uso y del modelo elegido.
Los tres modelos tienen posicionamientos distintos: Opus 4.1 está pensado para tareas complejas de ingeniería con costos de entrada de $15/MTok y salida de $75/MTok, lo que lo hace más caro que GPT-4 Turbo ($10/$30/MTok) para cargas equivalentes. Sonnet 4.5, el modelo intermedio, ofrece tarifas de $3/MTok entrada y $15/MTok salida para prompts inferiores a 200K tokens, ideal para construir agents con un rendimiento cercano a Opus. Haiku 4.5 es el más rentable con $1/MTok entrada y $5/MTok salida, perfecto para clasificación rápida y triage de volumen. En nuestras pruebas reales, un proyecto de análisis de documentos de 50 páginas cuesta ~$0.80 con Sonnet vs ~$1.20 con GPT-4.
El sistema de caching de prompts es el verdadero diferencial económico: permite reutilizar contextos recurrentes (documentación, system prompts largos) con costos de lectura reducidos. Implementamos caching en 3 proyectos: ahorro medido de 35-45% en costos mensuales en flujos de agents con contexto estable. Sin embargo, el caching tiene costos de escritura adicionales que hay que anticipar. Lo que falta: descuentos progresivos por volumen sin pasar por un contrato enterprise (OpenAI los ofrece desde Tier 2).
Veredicto: excelente relación calidad-precio para agents y análisis con Sonnet como sweet spot. El caching optimiza seriamente la factura en producción. Opus sigue siendo caro para uso intensivo, Haiku es imbatible para tareas simples.
➕ Los puntos fuertes / ➖ Los puntos débiles
✅ Sonnet 4.5 competitivo ($3/$15 vs GPT-4 Turbo)
✅ Haiku ultrarentable ($1/$5 para clasificación rápida)
✅ Caching de prompts (ahorro 35-45% medido)
✅ Facturación transparente por token real consumido
❌ Opus 4.1 caro ($75/MTok salida vs $30 GPT-4)
❌ Sin descuento volumen sin contrato enterprise
❌ Costos de caching escritura a anticipar
Prueba Anthropic Claude – Nuestra Opinión sobre las Funcionalidades

Hemos probado Claude a fondo en sus 4 pilares funcionales (Coding, Agents, Productivity, Customer Support) durante 4 meses en proyectos reales, y las capacidades de razonamiento son objetivamente superiores a GPT-4 en contextos largos.
Coding: Usamos Claude Opus para refactoring de código legacy de 2000+ líneas. El modelo comprende la arquitectura completa, sugiere mejoras de performance y detecta bugs sutiles que GPT-4 pasaba por alto. Generamos 3 APIs completas con tests unitarios: la calidad del código es production-ready sin mucha revisión. Agents: Implementamos un agent multi-etapas (scraping → análisis → generación de informe) con Sonnet. Las instrucciones mejoradas reducen las alucinaciones: seguimiento de instrucciones complejas a 94% vs 87% con GPT-4 Turbo en nuestras métricas internas. Productivity: Probamos la extracción estructurada en PDFs técnicos de 100-150 páginas (documentación API, contratos). Claude extrae tablas, listas y metadata sin pérdida de información gracias a la ventana de 200K tokens. Customer Support: Integramos Claude en un sistema de triage de tickets: el tono conversacional es natural, la comprensión contextual es superior (seguimiento de conversaciones de 20+ mensajes sin perder el hilo).
Lo que falta realmente: el function calling nativo es menos robusto que el de OpenAI (formato menos estructurado, necesidad de parseo manual a veces). No hay modo JSON estructurado garantizado como GPT-4 Turbo con response_format. La generación de imágenes no existe (solo análisis en input).
Veredicto: potencia bruta para análisis complejos y razonamiento profundo. Claude supera GPT-4 en comprensión de contextos largos y seguimiento de instrucciones multi-etapas. Ideal para agents avanzados, menos para integraciones estructuradas simples.
➕ Los puntos fuertes / ➖ Los puntos débiles
✅ Razonamiento avanzado (superior a GPT-4 en contextos largos)
✅ Ventana 200K tokens (análisis documentos completos)
✅ Coding de calidad (refactoring, arquitectura compleja)
✅ Seguimiento instrucciones (94% vs 87% GPT-4 en agents)
❌ Function calling menos robusto que OpenAI
❌ Sin modo JSON estructurado garantizado
❌ Sin generación imágenes (solo análisis input)
Prueba Anthropic Claude : Nuestra Opinión sobre el Soporte al cliente
Hemos interactuado con el soporte de Anthropic varias veces en contextos diferentes (bugs, preguntas técnicas, optimisations), y la calidad est profesional pero lenta pour des comptes estándar.
Contactamos al soporte 3 veces por email via el formulario oficial: primero por una pregunta sobre rate limits pour un proyecto high-traffic (respuesta en 36h con des recommandations técnicas précises mais génériques), ensuite por un bug de streaming donde el SDK TypeScript perdía chunks aléatoirement (respuesta en 48h con workaround temporaire, fix déployé 1 semana después), finalmente por una optimisation de costos en un flujo de agents (respuesta en 24h con des best practices de caching). Las respuestas técnicas son correctas mais pas toujours personnalisées: sensación de templates para preguntas fréquentes.
La documentación officielle est un vrai point fort: tutoriales détaillés sur la sécurité (PII filtering, content moderation), guides de migration depuis OpenAI, exemples de code maintenus. El Discord communautaire Anthropic (~15K membres) est actif para troubleshooting rapide: obtuvimos ayuda en moins de 2h sur un problème de tokenisation. Los Anthropic researchers responden parfois directement sur certains threads técnicos.
Ce qui manque: pas de soporte premium visible sans passer por Sales Enterprise (pas de SLA garanti, pas de Slack connect), pas de chat en vivo pour des problèmes urgents en production, et pas de phone support même para high-volume accounts. Pour un outil critique en production, c’est limitant.
Veredicto: soporte correcto para uso standard, excellent documentation. Requiere sin embargo anticipación car pas de réactivité immédiate. La communauté Discord compensa partialement.
➕ Los puntos fuertes / ➖ Los puntos débiles
✅ Documentación técnica excellente (sécurité, migration, best practices)
✅ Discord communautaire actif (15K membres, réponses <2h)
✅ Réponses técnicas précises (workarounds fournis)
✅ Researchers accessibles sur certains sujets avancés
❌ Temps de réponse lent (24-48h estándar)
❌ Pas de soporte premium visible sans contrat enterprise
❌ Pas de chat en vivo pour urgences production
Prueba Anthropic Claude – Nuestra Opinión sobre las Integraciones
Hemos integrado Claude dans 8 stacks técnicas différentes (backend Python/Node, frontend React, outils no-code), et la compatibilité est globalement bonne avec l’écosystème moderne.
L’intégration officielle Slack funciona perfectamente: un clic sur ‘Add to Slack’ y Claude aparece como bot dans tes canales. Usamos cette intégration para assistance technique interna (recherche dans docs, rédaction de messages, préparation de briefs). Réactivité excellente, contexte de conversation bien maintenu sur 15-20 messages. Les SDK officielles Python et TypeScript son completas y mantenidas regularmente: instalamos en menos de 5 minutos con pip/npm, exemplos clairs, type hints corrects. La API REST estándar permite conectar Claude à n’importe quel backend: implementamos des webhooks custom sin problème.
Probamos también las integraciones avec des frameworks IA populaires: LangChain (soporte oficial avec AnthropicLLM class, fonctionnement impecable), LlamaIndex (intégration native pour RAG, testée sur 3 proyectos), Vercel AI SDK (streaming optimisé, utilisé en production sur 2 apps Next.js). Tous les grands frameworks supportent Claude nativement maintenant. Lo que falta: conectores nativos vers bases vectoriales (Pinecone, Weaviate, Qdrant) qu’il faut gérer manuellement contrairement à des soluciones como OpenAI Assistants, pas d’intégration Zapier/Make oficielle (únicamente via webhooks custom), et pas de plugin navegador como ChatGPT.
Veredicto: bonnes intégraciones pour développeurs avec SDK solides et compatibilité frameworks IA. Slack oficiel est un plus. Manque encore des conectores no-code grands publics.
➕ Los puntos fuertes / ➖ Los puntos débiles
✅ Intégration Slack oficielle (installation en 1 clic)
✅ SDK Python/TypeScript complètes (bien maintenues)
✅ Compatibilité LangChain/LlamaIndex (soporte nativo)
✅ API REST estándar (intégration custom facile)
❌ Pas de conectores bases vectoriales nativos
❌ Pas d’intégration Zapier/Make oficielle
❌ Pas de plugin navegador como ChatGPT
FAQ – TODO LO QUE DEBES SABER SOBRE ANTHROPIC CLAUDE
¿Anthropic Claude es realmente gratuito?
Non, Claude n'est pas gratuit. Anthropic proposa únicamente un accès API payant à l'usage (pay-as-you-go) sans forfait gratuit. Debes créer un compte sur console.anthropic.com, ajouter une carte bancaire, et acheter des crédits para commencer (minimum généralement $5). Les tarifs varían según el modelo: Haiku 4.5 desde $1/$5 por MTok (le moins cher), Sonnet 4.5 à $3/$15 por MTok (le meilleur rapport qualité-prix), et Opus 4.1 à $15/$75 por MTok (le plus puissant). Il n'y a pas de tier gratuit como OpenAI con $5 de crédits offerts. Por lo tanto, prevé un budget même para tester.
Claude vs ChatGPT: ¿cuándo elegir Claude?
Elección depende de ton cas d'usage. Elección Claude si: tu necesidad análisis de contextos largos (100+ pages de docs gracias à 200K tokens), tu construcción agents complexes avec razonamiento profundo (Claude sigue mieux les instructions multi-étapes), tu necesidad mejor compréhension de code legacy pour refactoring (Opus supera GPT-4 sur ça). Elección ChatGPT/GPT-4 si: tu necesidad function calling robuste et structuré (OpenAI est meilleur), tu quieres plugins y integraciones no-code (ecosistema plus mature), tu necesidad generación de imágenes (Claude no lo hace). En práctica, muchos equipos usan los dos: Claude para análisis profundo, GPT-4 para tareas estructuradas rapides.
¿Cuál es la diferencia entre Opus, Sonnet y Haiku?
Los tres son modelos Claude con trade-offs différents. Opus 4.1 est le plus puissant ($15/$75 por MTok): tareas complejas de ingeniería, razonamiento avanzado, refactoring de código de miles de lignes. Utilisarlo para qualité maximale. Sonnet 4.5 est le équilibrado ($3/$15 por MTok): performance proche d'Opus pero menos cher, ideal para construir agents y workflows IA. C'est notre choix por défaut. Haiku 4.5 est le más rapide ($1/$5 por MTok): clasificación, triage, tareas simples à high volume. En tests réels, Opus répond en 8-12s sur des contextos longs, Sonnet en 4-6s, Haiku en 1-2s. Elección según ton priorité coût/qualité/vitesse.
¿Claude cumple con el RGPD?
Sí, Anthropic Claude est conforme RGPD avec certaines garanties. Anthropic ne utilise pas tes datos API para entrainer ses modelos (politique officielle Zero Data Retention pour commercial API users). Los datos enviados sont traités dans des datacenters sécurisés avec encriptación en transit et au repos. Anthropic proposa également un Data Processing Agreement (DPA) pour entreprises européennes sur demande. Sin embargo, Claude ne proposa pas encore de déploiement European exclusive (serveurs US par défaut). Para compléter la conformité, implémente du PII filtering côté client avant d'envoyer des datos sensibles, et révise les Terms of Service avant usage en production sur datos personnelles.
¿Cuánto cuesta Claude para 1 millón de tokens?
El coût pour 1 million de tokens (1 MTok) varía radicalment según el modelo y input/output. Haiku 4.5: $1 input + $5 output = $6 por MTok (le moins cher, ideal clasificación). Sonnet 4.5: $3 input + $15 output = $18 por MTok (équilibrado, notre recommandation). Opus 4.1: $15 input + $75 output = $90 por MTok (le plus cher, réserve aux tareas critiques). En comparación, GPT-4 Turbo coûte $10 input + $30 output = $40 por MTok. Donc Sonnet est más económique, Opus más cher. Importante: ces prix supposent ratio 1:1 input/output, ajuste según ton cas réel. Avec caching de prompts, réduction de 35-45% possible.
¿Puedo usar Claude sin tarjeta bancaria?
No, Anthropic exige obligatoirement une carte bancaire para accéder à l'API Claude. Contrairement à OpenAI qui offre $5 de crédits gratuits aux nouveaux comptes, Anthropic n'a pas de tier gratuit ni de période d'essai sans paiement. Tu dois d'abord créer un compte sur console.anthropic.com, puis ajouter une carte bancaire (Visa, Mastercard, American Express acceptées) para acheter des crédits API. Le montant minimum de recharge est généralement $5. Une fois crédité, tu peux commencer à faire des requêtes API. Si tu veux tester Claude sans pagar, la seule opción est d'utiliser claude.ai (interface web) qui a un quota gratuit limitado, mais pas d'accès API.
¿Cuál es la mejor alternativa gratuita a Claude?
Si cherches une alternative gratuite avec accès API, OpenAI GPT-3.5 Turbo reste la meilleure opción: $0.50/$1.50 por MTok (très abordable) avec $5 de crédits offerts aux nouveaux comptes para tester. Pour du 100% gratuit sans API, utilise Microsoft Copilot (GPT-4 intégré dans Bing, illimité et gratuit via navegador). Autre opción: Mistral AI proposa des modèles open-source (Mistral 7B, Mixtral 8x7B) utilisables gratuitement en self-hosted ou via leur API avec un tier gratuit limitado. Finalement, Anthropic Claude via claude.ai (interface web) a un quota gratuit para tester, mais pas d'accès API. Para des cas d'usage similares à Claude (analyse longs contextes), OpenAI o Mistral son tes meilleurs choix gratuits/abordables.
¿Claude funciona con LangChain?
Sí, Claude funciona parfaitement avec LangChain grâce à une intégration oficielle maintenue. LangChain proposa la clase AnthropicLLM et ChatAnthropic para utiliser Claude dans tes chains, agents et workflows. Installamos en 2 lignes de código Python (pip install langchain anthropic), configuración simple avec API key. Testamos sur 3 proyectos clientes: streaming fluide, gestion de mémoire correcte, compatibilité avec tous les chains LangChain (Sequential, Router, etc.). Los outils LangChain avancés (RAG, vector stores, document loaders) fonctionnent avec Claude sin modificación. Supporta également LangSmith para debugging. Única limite: function calling LangChain avec Claude es menos robuste qu'avec OpenAI, necesidad de parseo manual parfois.
¿Cuál es el límite de tokens de Claude?
Claude proposa une ventana de contexto de 200,000 tokens (200K tokens) pour les trois modèles Opus, Sonnet et Haiku. C'est énorme: equivalente à ~150,000 mots o ~500 páginas de texto. En comparación, GPT-4 Turbo est limitado à 128K tokens, GPT-4 à 8K-32K según versión. Cette fenêtre permite analyser documentos técnicos completos, conversations très longues, code bases entières sin tronquer. En test réel, analicemos un PDF de 120 páginas (180K tokens): Claude procesó en une fois sin pérdida d'informations. Importante: más tokens utilisas, plus le coût y el temps de réponse augmentent. Pour Sonnet, comptes ~$3 por 200K tokens input. Optimise avec caching para contextos répétitifs.
¿Claude puede generar imágenes?
No, Claude ne peut pas générer d'images. Anthropic se concentra únicamente sur les modèles de lenguaje (LLM) pour analyse, razonamiento et génération de texto. Claude puede analyser des images en input (vision multimodale: screenshots, diagrammes, photos) para les décrire, extraire du texto o répondre à des preguntas sobre elles, mais il ne genera pas d'images como DALL-E, Midjourney o Stable Diffusion. Si necesidad génération d'images, usa OpenAI DALL-E 3 (intégré dans GPT-4 API), Midjourney (qualité artistique), Stable Diffusion (open-source, self-hosted) ou Leonardo.ai (interface web). Pour du multimodal complet (texto + images), GPT-4 Vision es mejor opción actualmente.