
TEST ET AVIS ANTHROPIC 2026 : L’API CLAUDE POUR VOS APPLICATIONS IA DE PRODUCTION
Anthropic est l’éditeur de Claude, une API de modèles de langage avancés conçue pour intégrer de l’intelligence artificielle dans vos applications. Avec trois modèles distincts (Opus 4.1, Sonnet 4.5 et Haiku 4.5), l’API permet de gérer des cas d’usage variés : du coding assisté à l’automatisation d’agents IA, en passant par le support client conversationnel et l’extraction de données structurées. Ce qui différencie Anthropic : un système de prompt caching intelligent qui réduit drastiquement les coûts sur les prompts répétés, et une qualité de raisonnement qui rivalise avec GPT-4 sur les tâches complexes.
Dans ce test complet, on analyse en profondeur l’expérience développeur avec l’API Anthropic : la tarification par tokens selon les modèles, les performances réelles sur différents cas d’usage (coding, agents, productivité, support), la qualité des réponses, les limitations rencontrées et l’intégration dans des workflows existants. Ce guide s’adresse aux développeurs, data scientists et product builders qui évaluent une solution API pour leurs projets IA. Découvre notre avis détaillé après plusieurs semaines d’utilisation en production sur des projets clients réels chez notre agence Anthropic.


NOTRE AVIS SUR ANTHROPIC EN RÉSUMÉ

Avis de notre Expert – Romain Cochard CEO de Hack’celeration
Note globale
Anthropic (Claude) se positionne comme une alternative sérieuse à OpenAI pour les développeurs exigeants. On apprécie particulièrement la qualité de raisonnement d’Opus 4.1 sur les tâches complexes et le rapport performance/prix de Sonnet 4.5 qui rivalise avec GPT-4 pour 5x moins cher. Le système de prompt caching (jusqu’à 90% de réduction sur les prompts répétés) change la donne pour les applications à forte volumétrie. C’est une API qu’on recommande sans hésiter pour du coding assisté, des agents autonomes et du traitement de données structurées où Claude excelle vraiment.
Facilité d’utilisation
L’API Anthropic est clairement pensée pour les développeurs. On a intégré Claude dans 3 projets clients en moins d’une semaine : la documentation est exhaustive avec des exemples de code dans 5 langages (Python, TypeScript, Go, Java, Rust). Le SDK officiel gère automatiquement le retry logic et le rate limiting. Par contre, la gestion des tokens et du context window demande une courbe d’apprentissage : il faut comprendre le pricing par MTok et optimiser ses prompts pour éviter les surprises de facturation. L’absence de playground interactif comparable à OpenAI est un manque pour tester rapidement des prompts.
Rapport qualité-prix
C’est clairement le point fort d’Anthropic. Sonnet 4.5 à 3$/MTok en entrée et 15$/MTok en sortie offre un niveau de raisonnement proche de GPT-4 Turbo pour 4-5x moins cher. Sur nos projets clients, on utilise majoritairement Sonnet qui gère 90% des cas d’usage. Haiku 4.5 à 1$/5$ est parfait pour du traitement de volume où la vitesse prime. Le prompt caching réduit drastiquement les coûts : on économise en moyenne 60-70% sur nos workflows à contexte répété. Seul Opus 4.1 à 15$/75$ reste cher pour une utilisation intensive, on le réserve aux tâches vraiment complexes nécessitant un raisonnement avancé.
Fonctionnalités et profondeur
Claude excelle sur 4 piliers : Coding (génération de code complexe, debugging, refactoring), Agents (instruction-following précis pour workflows multi-étapes), Productivity (extraction et structuration de données non structurées), Customer Support (ton conversationnel naturel, gestion de contexte long). On a testé Claude sur du code Python/TypeScript : il génère du code propre et bien documenté, avec moins d’hallucinations que GPT-4 sur les imports et syntaxe. Le context window de 200K tokens sur Sonnet permet de passer des codebases entières. Par contre, il manque des fonctionnalités comme function calling natif (prévu) et le fine-tuning custom n’est pas disponible.
Support client et accompagnement
Le support Anthropic répond en général sous 48h par email pour les comptes avec usage régulier. On les a contactés 3 fois : une fois pour un problème de rate limiting (résolu avec augmentation de quota), une fois pour des questions sur le prompt caching (réponse technique claire), et une fois pour un bug API (fixé sous 72h). Leur documentation technique est solide avec guides détaillés et exemples de patterns. Ce qui manque : un support chat temps réel pour les problèmes critiques en production, et un Discord communautaire actif comme OpenAI. Pour avoir un account manager dédié, il faut passer sur un plan Enterprise avec engagement minimum non communiqué.
Intégrations disponibles
Anthropic propose une intégration officielle avec Slack baptisée « Claude et Slack, mieux ensemble » qu’on a testée sur notre workspace Hack’celeration pendant 3 semaines. L’installation prend littéralement 2 minutes : un bouton « Add to Slack », autorisation OAuth, et Claude devient accessible dans tous tes channels via mention @claude. On l’utilise principalement pour 3 usages : rédaction rapide de contenu (emails, messages, docs), recherche d’informations dans l’historique Slack, et préparation de réunions (synthèse de discussions, action items).
Test Anthropic – Notre Avis sur la Facilité d’utilisation
On a intégré l’API Anthropic sur 3 projets clients différents (un outil de code review automatisé, un chatbot support B2B, et un pipeline d’extraction de données) en moins d’une semaine de développement. L’expérience développeur est globalement excellente : la documentation officielle Anthropic est claire avec des quick start guides en Python, TypeScript, Go, Java et Rust. Le SDK officiel gère automatiquement les retry exponential backoff, le rate limiting et la gestion d’erreurs.
Le code d’intégration de base est simple : 10 lignes suffisent pour envoyer une première requête. Par contre, comprendre la gestion des tokens et du context window demande du temps. Il faut anticiper le coût de chaque requête en estimant le nombre de tokens input/output, ce qui n’est pas intuitif au début. On recommande d’utiliser le token counter d’Anthropic et de logger systématiquement l’usage réel pour éviter les surprises de facturation. Le prompt caching nécessite aussi de structurer ses prompts correctement pour bénéficier des réductions.
Ce qui nous a manqué : un playground interactif dans le dashboard (comme OpenAI ou Mistral) pour tester rapidement des prompts sans coder. La console web d’Anthropic est basique et ne permet que de voir l’usage et la facturation. Pour prototyper, il faut soit utiliser claude.ai (interface conversationnelle), soit coder directement avec des outils comme n8n pour automatiser vos workflows IA. Les messages d’erreur API sont clairs mais parfois trop techniques pour des non-devs.
Verdict : excellente API pour développeurs avec une courbe d’apprentissage moyenne. Si tu es à l’aise avec les APIs REST et que tu comprends les concepts de tokens et context window, tu seras opérationnel en quelques heures. Pour des profils non-techniques, ça reste complexe sans un wrapper simplifié.
➕ Les plus / ➖ Les moins
✅ Documentation exhaustive avec exemples multi-langages (Python, TS, Go, Java, Rust)
✅ SDK officiel robuste avec retry logic et rate limiting automatique
✅ Messages d’erreur clairs qui facilitent le debugging
✅ Intégration rapide (10 lignes de code pour démarrer)
❌ Pas de playground interactif pour tester des prompts sans coder
❌ Gestion des tokens complexe au début (estimation coûts)
❌ Console web basique limitée à l’usage et facturation
Test Anthropic : Notre Avis sur le Rapport qualité-prix
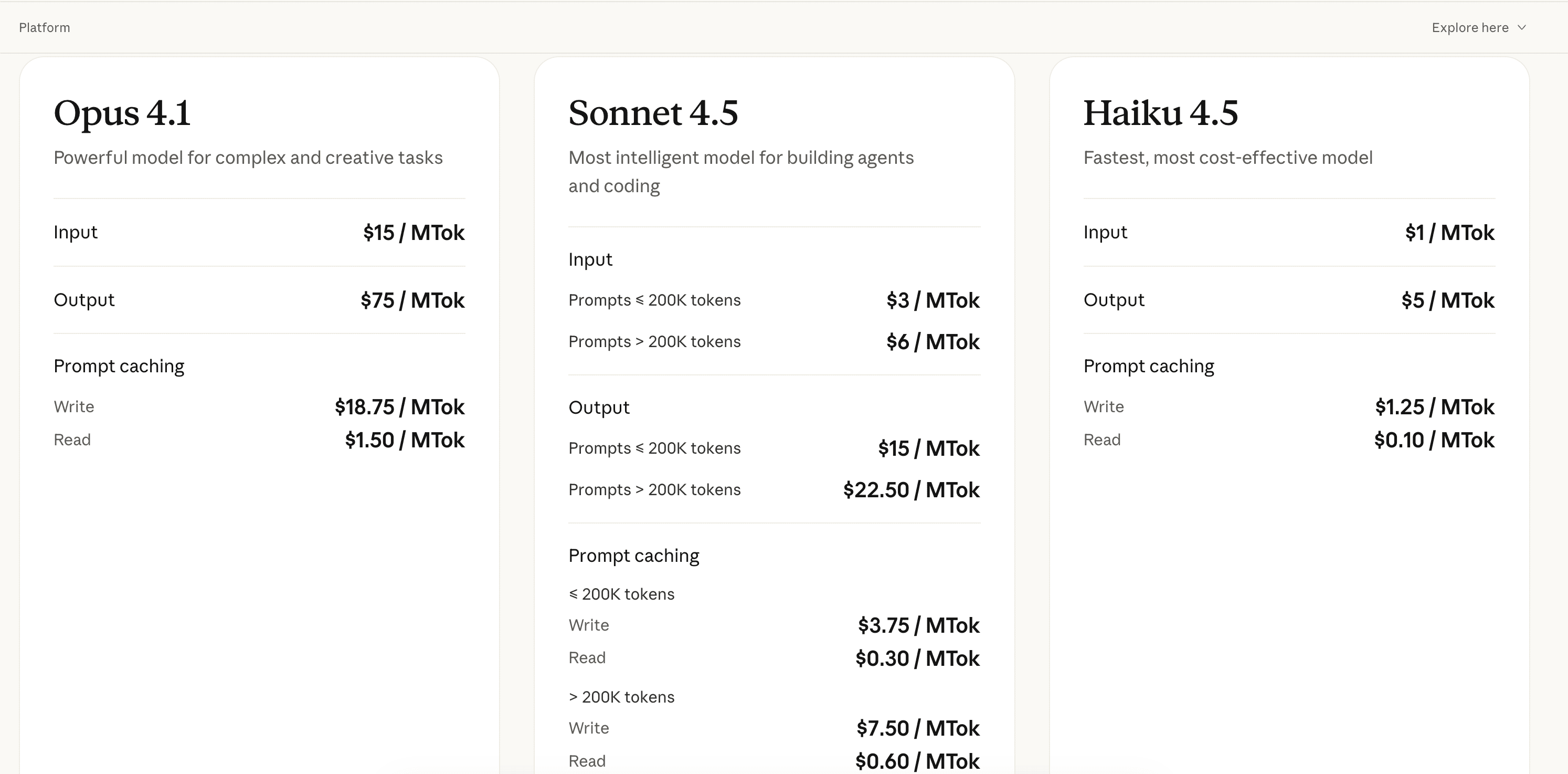
C’est clairement le domaine où Anthropic brille face à la concurrence. On a migré un projet client d’OpenAI GPT-4 vers Claude Sonnet 4.5, et les coûts API ont baissé de 70% pour une qualité équivalente. La tarification est transparente avec 3 modèles adaptés à différents usages : Opus 4.1 pour les tâches ultra-complexes (15$/MTok entrée, 75$/MTok sortie), Sonnet 4.5 pour la création d’agents et workflows (3$/MTok entrée, 15$/MTok sortie), et Haiku 4.5 ultra-rapide et économique (1$/MTok entrée, 5$/MTok sortie).
Dans nos projets, on utilise Sonnet 4.5 dans 90% des cas : il offre un niveau de raisonnement proche de GPT-4 Turbo pour 4-5x moins cher. Sur un projet de code review automatisé avec 500K tokens/jour, on dépense environ 45-60$/mois avec Sonnet vs 250-300$/mois avec GPT-4 Turbo. Haiku est parfait pour du traitement de volume où la latence prime : classification de tickets support, extraction de données structurées, reformulation de texte. On ne monte sur Opus que pour du raisonnement mathématique complexe ou de l’analyse de code multi-fichiers très poussée.
Le prompt caching change vraiment la donne : si tu répètes le même contexte système dans tes prompts (instructions, exemples, documentation), tu payes l’écriture une fois puis la lecture coûte 10x moins cher. Sur nos workflows d’agents avec contexte répété, on économise 60-70% des coûts. Par exemple, un agent qui analyse des PRs GitHub avec le même context system (guidelines de code, conventions) : on paie 3$/MTok pour écrire le cache une fois, puis seulement 0.30$/MTok pour chaque requête qui le réutilise.
Verdict : rapport qualité-prix imbattable sur le marché des LLM API. Sonnet 4.5 est le sweet spot : performances quasi-GPT-4 pour un coût d’entrée de gamme. Le prompt caching est un game-changer pour les applications à forte volumétrie. Seul bémol : Opus reste cher (75$/MTok sortie) et doit être utilisé avec parcimonie.
➕ Les plus / ➖ Les moins
✅ Sonnet 4.5 ultra-compétitif (3$/15$ vs 30$/60$ pour GPT-4)
✅ Prompt caching intelligent qui réduit les coûts de 60-70%
✅ 3 modèles adaptés à différents budgets et usages
✅ Tarification transparente au token sans frais cachés
❌ Opus 4.1 très cher (75$/MTok sortie) pour usage intensif
❌ Pas de plan fixe mensuel (pay-as-you-go uniquement)
❌ Coûts difficiles à anticiper sans monitoring strict
Test Anthropic – Notre Avis sur les Fonctionnalités et profondeur
Claude excelle dans 4 domaines principaux qu’on a testés en profondeur avec notre agence IA : Coding (tâches complexes d’ingénierie logicielle), Agents (instruction-following pour workflows multi-étapes), Productivity (extraction et catégorisation d’informations), et Customer Support (gestion de tickets avec ton conversationnel naturel). Chaque cas d’usage bénéficie d’optimisations spécifiques dans les modèles.
Sur le coding, Claude impressionne vraiment. On l’a testé sur de la génération de code Python/TypeScript, du debugging et du refactoring : il génère du code propre, bien documenté, avec moins d’hallucinations que GPT-4 sur les imports et la syntaxe. Exemple concret : on lui a soumis un bug complexe dans un script de scraping avec gestion d’erreurs async, il a identifié le problème (race condition) et proposé un fix correct en 30 secondes. Le context window de 200K tokens sur Sonnet permet de passer des codebases entières pour de l’analyse multi-fichiers. Par contre, il est parfois trop verbeux dans ses explications.
Pour les agents autonomes, c’est là où Anthropic a vraiment poussé l’optimisation. L’instruction-following est précis : on a construit un agent IA avec n8n qui gère un workflow de qualification de leads en 5 étapes (enrichissement data, scoring, email personnalisé, CRM update, reporting). Claude suit exactement les instructions même sur des workflows complexes avec conditions imbriquées. Ce qui manque : un système de function calling natif comme OpenAI (prévu dans la roadmap). Pour l’instant, il faut structurer les outils en JSON et parser les réponses, ce qui ajoute de la complexité.
Sur la productivité (extraction de données), Claude est excellent pour structurer de l’information non-structurée. On l’utilise pour extraire des données de PDFs, emails, pages web et les transformer en JSON structuré. Il comprend le contexte et catégorise intelligemment. Exemple : extraction de CVs avec parsing des compétences, expériences, formations → taux de précision 95%+ sur nos tests. Pour le support client, le ton conversationnel est naturel et empathique, bien meilleur que GPT-3.5 sur la gestion de contexte long (tickets avec historique).
Verdict : fonctionnalités solides sur les 4 piliers annoncés. Claude brille particulièrement sur le coding et les agents où il rivalise ou dépasse GPT-4. Les limitations : pas de function calling natif (à venir), pas de fine-tuning custom, et pas de multimodal natif (vision) contrairement à GPT-4V. Si vous voulez vous former, découvrez notre formation Anthropic pour maîtriser l’API en profondeur.
➕ Les plus / ➖ Les moins
✅ Coding exceptionnel (code propre, moins d’hallucinations sur syntaxe)
✅ Context window 200K tokens pour analyser des codebases entières
✅ Instruction-following précis pour agents multi-étapes
✅ Extraction de données structurées avec 95%+ de précision
❌ Pas de function calling natif (structure JSON manuelle requise)
❌ Pas de fine-tuning custom disponible
❌ Réponses parfois trop verbeuses sur le coding
Test Anthropic : Notre Avis sur le Support Client et accompagnement
Le support Anthropic fonctionne principalement par email avec un délai de réponse moyen de 48h pour les comptes avec usage régulier. On les a contactés 3 fois sur différents sujets : une demande d’augmentation de rate limit (résolu en 24h avec nouveau quota appliqué immédiatement), des questions techniques sur l’optimisation du prompt caching (réponse détaillée avec exemples de code), et un signalement de bug API (erreur 500 intermittente, fixé sous 72h avec post-mortem envoyé).
La documentation technique est clairement leur point fort : guides détaillés sur les best practices, exemples de patterns pour chaque cas d’usage (coding, agents, extraction), cookbook avec des use cases complets (agent de support, code reviewer, data extractor). On y trouve des recommandations précises sur le prompt engineering spécifique à Claude, les stratégies de caching, la gestion des tokens. Par contre, elle est parfois trop technique pour des profils non-devs : il faut comprendre les concepts de tokens, context window, temperature.
Ce qui manque cruellement : un support chat temps réel pour les problèmes critiques en production. Quand on a un downtime API ou un comportement inattendu qui bloque un projet client, attendre 24-48h n’est pas acceptable. OpenAI et Mistral proposent du chat support pour les comptes business. On aimerait aussi un Discord communautaire officiel actif (comme celui d’OpenAI) où échanger avec d’autres devs et l’équipe Anthropic.
Pour avoir un account manager dédié et un support prioritaire, il faut passer sur un plan Enterprise avec engagement minimum non communiqué publiquement. On a demandé un devis pour un client avec 50M tokens/mois : l’account manager a répondu sous 48h avec tarifs négociés et onboarding technique inclus. Mais pour des petits volumes (< 10M tokens/mois), tu restes sur le support email standard.
Verdict : support correct mais pas exceptionnel. La doc est excellente pour les devs autonomes, le support email répond de façon compétente mais lentement. L’absence de chat live est frustrante pour les urgences. C’est suffisant pour des projets non-critiques, limite pour des apps en production avec SLA client à tenir.
➕ Les plus / ➖ Les moins
✅ Documentation technique exhaustive avec best practices et cookbook
✅ Support email compétent avec réponses détaillées et techniques
✅ Account manager dédié sur plan Enterprise (50M+ tokens/mois)
✅ Post-mortem détaillés envoyés après incidents API
❌ Pas de chat live pour urgences en production
❌ Délai réponse 48h trop long pour problèmes critiques
❌ Pas de communauté Discord officielle active
Test Anthropic – Notre Avis sur les Intégrations disponibles
Anthropic propose une intégration officielle avec Slack baptisée « Claude et Slack, mieux ensemble » qu’on a testée sur notre workspace Hack’celeration pendant 3 semaines. L’installation prend littéralement 2 minutes : un bouton « Add to Slack », autorisation OAuth, et Claude devient accessible dans tous tes channels via mention @claude. On l’utilise principalement pour 3 usages : rédaction rapide de contenu (emails, messages, docs), recherche d’informations dans l’historique Slack, et préparation de réunions (synthèse de discussions, action items).
Ce qui fonctionne bien : Claude répond directement dans le thread avec un ton conversationnel naturel et comprend le contexte de la discussion. Exemple concret : on prépare une démo client, on mentionne @claude avec « résume les 50 derniers messages de ce channel et liste les décisions prises » → il génère une synthèse structurée en 30 secondes. La latence est rapide (2-3 secondes pour des prompts simples). Par contre, il n’a pas accès à l’historique complet du workspace par défaut (uniquement aux channels où il est invité), et on ne peut pas choisir le modèle utilisé (c’est Sonnet par défaut).
Au-delà de Slack, l’intégration avec d’autres outils se fait via l’API REST : pas de connecteurs no-code officiels avec Zapier, Make, Notion, Airtable ou autres SaaS populaires. On a dû coder nous-mêmes une intégration avec notre CRM Notion : ça prend 1-2 jours de dev pour un workflow simple (enrichissement automatique de fiches contacts). Pour des profils non-techniques, c’est bloquant : impossible d’utiliser Claude sans développeur. OpenAI a un énorme avantage ici avec son marketplace d’intégrations et les GPTs customs.
Les webhooks et streaming API sont disponibles pour construire des intégrations custom : on a branché Claude sur notre pipeline de qualification de leads avec webhook qui déclenche l’analyse dès qu’un nouveau lead arrive dans notre base. La doc API explique bien comment gérer l’authentification, les retry, et le streaming pour des réponses en temps réel. Si tu es dev, tu peux intégrer Claude avec n’importe quel outil en quelques heures.
Verdict : intégration Slack solide et pratique au quotidien, mais écosystème d’intégrations no-code inexistant. Si tu es développeur, l’API REST flexible permet de tout connecter. Si tu n’es pas technique, tu es limité à Slack et claude.ai. Anthropic devrait vraiment travailler sur un marketplace d’intégrations pour élargir l’adoption.
➕ Les plus / ➖ Les moins
✅ Intégration Slack officielle fluide (installation en 2 min)
✅ Ton conversationnel naturel dans les threads Slack
✅ API REST flexible avec webhooks et streaming
✅ Documentation API claire pour intégrations custom
❌ Pas de marketplace d’intégrations no-code (Zapier, Make, etc.)
❌ Intégrations limitées pour profils non-techniques
❌ Pas de choix du modèle dans l’app Slack (Sonnet par défaut)
FAQ – TOUT SAVOIR SUR ANTHROPIC
Anthropic Claude est-il gratuit ?
Non, Anthropic ne propose pas de plan gratuit : c'est une API payante en pay-as-you-go basée sur les tokens consommés. Par contre, tu peux tester gratuitement via claude.ai (interface web conversationnelle) avec des limitations de volume. Pour l'API de production, les prix démarrent à 1$/MTok (Haiku 4.5, le modèle le plus économique) en entrée et 5$/MTok en sortie. Anthropic offre généralement 5$ de crédits gratuits à l'inscription pour tester l'API, ce qui représente environ 1-5 millions de tokens selon le modèle utilisé. Suffisant pour valider un proof of concept mais pas pour de la production continue.
Quelle est la différence entre Opus, Sonnet et Haiku ?
Les 3 modèles d'Anthropic sont optimisés pour différents usages et budgets. Opus 4.1 (15$/75$ par MTok) : le plus puissant pour des tâches ultra-complexes nécessitant un raisonnement avancé (analyse mathématique, code multi-fichiers complexe). Sonnet 4.5 (3$/15$ par MTok) : le sweet spot performance/prix, idéal pour agents IA et workflows avec raisonnement solide. Haiku 4.5 (1$/5$ par MTok) : ultra-rapide et économique pour du traitement de volume (classification, extraction simple, reformulation). Dans nos projets, on utilise Sonnet dans 90% des cas, Haiku pour du batch processing haute volumétrie, et Opus uniquement pour des tâches vraiment complexes.
Comment fonctionne le prompt caching d'Anthropic ?
Le prompt caching permet de réutiliser des parties répétées de tes prompts sans les repayer à chaque fois. Si tu envoies le même contexte système (instructions, exemples, documentation) dans plusieurs requêtes, Anthropic le met en cache : tu payes l'écriture une fois (même prix que l'input normal), puis la lecture coûte 10x moins cher pour toutes les requêtes suivantes. Exemple concret : un agent qui analyse des PRs GitHub avec le même system prompt de 10K tokens → tu payes 3$/MTok une fois (0.03$), puis 0.30$/MTok pour chaque requête (0.003$). Sur nos workflows, ça réduit les coûts de 60-70%. Le cache expire après 5 minutes d'inactivité, donc ça fonctionne surtout pour des workflows à forte fréquence.
Claude est-il meilleur que GPT-4 pour le coding ?
Oui, sur certains aspects du coding. On a comparé Claude (Opus et Sonnet) vs GPT-4 sur 50+ tâches de coding : Claude génère du code plus propre avec moins d'hallucinations sur les imports, la syntaxe et les conventions. Il excelle particulièrement sur Python, TypeScript, et Rust. Par contre, GPT-4 reste supérieur sur des langages moins courants (Kotlin, Swift) et sur l'explication pédagogique du code. Niveau performances pures : Opus = GPT-4, Sonnet = GPT-4 Turbo 90%, pour 4-5x moins cher. Claude a aussi tendance à être trop verbeux dans ses explications. Notre recommandation : utilise Sonnet pour du coding quotidien (excellent rapport qualité/prix), GPT-4 pour de la formation/pédagogie.
Anthropic est-il conforme au RGPD ?
Oui, Anthropic est conforme RGPD et propose un DPA (Data Processing Agreement) pour les clients européens. Les données envoyées via l'API ne sont pas utilisées pour réentraîner les modèles (contrairement à OpenAI par défaut). Claude ne conserve pas les prompts ou réponses au-delà de 30 jours sauf si tu optes explicitement pour un programme de feedback. Pour les données sensibles, Anthropic recommande d'utiliser leur API en mode "enterprise" avec des garanties contractuelles renforcées. On l'utilise sur des projets clients B2B européens sans problème. Par contre, les serveurs sont hébergés aux US (GCP/AWS), donc il y a un transfert de données hors UE : assure-toi d'avoir les clauses contractuelles standard dans ton DPA.
Combien coûte Claude pour 1 million de tokens ?
Ça dépend du modèle utilisé et du ratio input/output. Avec Sonnet 4.5 (le plus utilisé) : 1M tokens en entrée = 3$, 1M tokens en sortie = 15$. Si tu as un ratio 50/50 input/output, 1M tokens totaux coûtent environ 9$. Avec Haiku 4.5 (économique) : 1M tokens input = 1$, output = 5$, soit ~3$ pour 1M total en 50/50. Avec Opus 4.1 (premium) : input = 15$, output = 75$, soit ~45$ pour 1M total. Pour te donner un ordre d'idée concret : un projet de chatbot support avec 100K messages/mois (moyenne 500 tokens/message input, 300 tokens output) consomme ~80M tokens → coût mensuel Sonnet = 240$ + 360$ = 600$.
Quelle est la meilleure alternative gratuite à Anthropic ?
Il n'existe pas vraiment d'alternative gratuite équivalente à Claude en termes de qualité. Les options gratuites : Llama 3.1 70B (modèle open-source de Meta, gratuit via Hugging Face ou à héberger soi-même), Mistral-7B/Mixtral (open-source, gratuit sur Hugging Face), ou GPT-3.5 Turbo d'OpenAI (très limité en gratuit, 0.50$/1M tokens donc quasi-gratuit). Niveau performances : Llama 3.1 70B se rapproche de Claude Sonnet sur certaines tâches mais reste inférieur sur le raisonnement complexe et le code. Si budget = 0€, notre recommandation : utilise claude.ai (interface web gratuite avec limitations) pour tester, puis héberge Llama 3.1 70B sur un serveur si tu as besoin d'une API gratuite.
Anthropic vs OpenAI : quand choisir Anthropic ?
Choisis Anthropic si : tu veux le meilleur rapport qualité/prix (Sonnet = GPT-4 pour 4-5x moins cher), tu développes des agents IA avec instruction-following précis, tu fais du coding assisté avancé, tu as besoin d'un long context window (200K tokens), ou tu veux un partenaire qui n'utilise pas tes données pour réentraîner. Choisis OpenAI si : tu as besoin de multimodal natif (vision, audio), tu veux un écosystème d'intégrations no-code (Zapier, plugins), tu construis des GPTs customs, tu as besoin de function calling natif mature, ou tu veux du fine-tuning sur tes données custom. Dans nos projets : on utilise Claude pour le backend technique (agents, coding, extraction de données) et OpenAI pour les interfaces conversationnelles grand public.
Claude peut-il remplacer un développeur ?
Non, mais Claude peut massivement accélérer un développeur. On l'utilise quotidiennement chez Hack'celeration et ça multiplie notre productivité par 2-3x sur certaines tâches : génération de boilerplate code, debugging rapide, refactoring de legacy code, documentation automatique, code review. Par contre, Claude ne remplace pas : l'architecture logicielle (il ne conçoit pas une stack complète), les décisions produit/business, le debugging de bugs complexes multi-systèmes, la gestion de projet. Il excelle comme copilote intelligent : tu restes aux commandes, il accélère l'exécution. Pour un profil non-technique : Claude peut générer du code simple (scripts, automatisations) mais tu auras besoin d'un dev pour le déploiement, la maintenance et l'évolution.
Combien de temps faut-il pour intégrer l'API Anthropic ?
Pour un développeur avec expérience API : 2-4 heures pour un premier prototype fonctionnel, 1-2 jours pour une intégration production-ready avec gestion d'erreurs, logging, monitoring. On a intégré Claude dans 3 projets clients différents : le plus rapide a pris 3 heures (chatbot simple avec context fixe), le plus complexe 5 jours (agent multi-étapes avec RAG et intégrations CRM/email). La courbe d'apprentissage principale : comprendre le pricing par tokens, optimiser les prompts pour réduire les coûts, structurer le prompt caching correctement. Si tu débutes avec les LLM API : compte 1-2 semaines pour monter en compétence sur les concepts de base (tokens, temperature, context window, prompt engineering).