
TEST ET AVIS APIFY 2026 : LA PLATEFORME DE WEB SCRAPING CLOUD QUI SCALE
Apify est une plateforme cloud de web scraping et d’automatisation qui permet d’extraire des données de n’importe quel site web à grande échelle. Grâce à son Apify Store qui propose plus de 1500 Actors prêts à l’emploi (scripts de scraping), son API REST complète et sa gestion automatique des proxies et captchas, cet outil transforme des tâches d’extraction complexes en processus automatisés déployables en quelques clics.
Dans ce test complet, on analyse en profondeur les performances d’Apify : fonctionnalités de scraping, tarification par unité de calcul, qualité des Actors communautaires, intégrations techniques et limites réelles. Destiné aux développeurs, data analysts et growth hackers qui gèrent des volumes importants de données, ce test t’aide à déterminer si notre agence Apify mérite sa place dans ta stack d’automatisation. Découvre notre avis détaillé basé sur plusieurs semaines de tests en conditions réelles.


NOTRE AVIS SUR APIFY EN RÉSUMÉ

Avis de notre Expert – Romain Cochard CEO de Hack’celeration
Note globale
Apify se positionne comme une solution professionnelle pour le web scraping à grande échelle. On apprécie particulièrement la richesse de l’Apify Store avec ses 1500+ Actors prêts à l’emploi et la gestion automatique des proxies et captchas qui font gagner un temps fou. C’est un outil qu’on recommande sans hésiter pour les équipes tech qui gèrent des volumes importants d’extraction de données et ont besoin d’une infrastructure cloud fiable pour automatiser leur scraping sans gérer les serveurs.
Facilité d’utilisation
Apify nécessite des compétences techniques pour être exploité pleinement. Si les Actors prêts à l’emploi sont simples à lancer (quelques clics), créer ses propres scripts demande de maîtriser JavaScript/Python et l’architecture de la plateforme. On a formé un dev junior en 2 jours sur les bases, mais la courbe d’apprentissage est réelle. L’interface est claire mais dense : beaucoup de paramètres à comprendre (proxies, concurrency, memory). Par contre, la documentation est excellente avec des exemples de code concrets. Verdict : accessible pour des profils techniques, complexe pour des non-devs.
Rapport qualité-prix
Le modèle tarifaire d’Apify est basé sur les unités de calcul consommées. Le plan gratuit offre $5 de crédit à $0.3 par unité de calcul, largement suffisant pour tester plusieurs Actors et valider l’outil. Les plans payants démarrent à $39/mois pour le Starter avec chat support et réduction bronze, $199/mois pour Scale avec support prioritaire et $0.25/unité, jusqu’à $999/mois pour Business avec account manager et $0.2/unité. Ce qui monte vite : les gros volumes de scraping. Un projet client qui scrape 50k pages/jour nous coûte environ $150/mois. Comparé à gérer sa propre infra (serveurs, proxies, maintenance), le ROI reste positif. Par contre, Microsoft Playwright ou Puppeteer localement sont gratuits si tu as les compétences pour gérer l’infrastructure.
Fonctionnalités et profondeur
C’est là qu’Apify brille vraiment. L’Apify Store propose plus de 1500 Actors couvrant tous les cas d’usage : Google Maps Scraper (4.8 étoiles, 193K utilisateurs), Website Content Crawler pour alimenter des modèles d’IA (4.7 étoiles), TikTok Scraper (87K utilisateurs), Amazon, LinkedIn, Instagram, etc. Les fonctionnalités de scraping sont pro : gestion automatique des proxies résidentiels, bypass de captchas, rate limiting intelligent, retry automatique, scheduling avancé, stockage des datasets. On peut créer ses propres Actors en JavaScript ou Python, versionner via Git, et orchestrer des workflows complexes. Les APIs REST et webhooks permettent d’intégrer Apify dans n’importe quelle stack. Seul manque : une analyse automatique par IA des données scrapées.
Support client et accompagnement
Le support d’Apify est réactif et technique. Sur le plan gratuit, tu as accès au support communautaire via Discord (actif, réponses souvent en quelques heures). On a contacté le chat support du plan Starter 3 fois : une fois pour un bug de proxy (résolu en 24h), une fois pour optimiser la consommation de compute units (conseils pertinents), une fois pour une question sur l’API (réponse claire avec exemple de code). Le plan Scale offre un support prioritaire vraiment efficace : réponse sous 4h en moyenne selon notre expérience. La documentation technique est exhaustive avec des guides détaillés, des exemples de code et des vidéos tuto. Seul bémol : pas d’account manager sur les plans < $999/mois, ce qui limite l'accompagnement stratégique.
Intégrations disponibles
Apify s’intègre facilement dans n’importe quel workflow technique. L’API RESTful permet de connecter des services cloud ou locaux, lancer des runs, récupérer des datasets et monitorer l’exécution. Les Webhooks configurables déclenchent des actions automatiques basées sur des événements système (run terminé, erreur détectée, dataset mis à jour). L’intégration GitHub permet de créer des issues automatiquement lors d’échecs d’exécution d’Actor, pratique pour le debugging en équipe. On peut importer du code directement depuis GitHub, GitLab ou Bitbucket lors de la création d’un Actor. Apify se connecte nativement avec Zapier, Make, Airbyte pour push les données vers des CRM, bases de données ou outils d’analytics. On utilise l’API pour alimenter automatiquement Airtable avec les données scrapées, ça marche parfaitement.
Test Apify – Notre Avis sur la Facilité d’utilisation
On a testé Apify en conditions réelles sur plusieurs projets clients nécessitant du scraping à grande échelle, et c’est clairement un outil pensé pour des profils techniques. Si tu sais coder en JavaScript ou Python, la prise en main est progressive. Si tu débutes en scraping, la courbe d’apprentissage est réelle.
Le gros avantage d’Apify, c’est l’Apify Store avec ses 1500+ Actors prêts à l’emploi. Lancer un scraping de Google Maps ou TikTok prend littéralement 3 minutes : tu sélectionnes l’Actor, tu configures les paramètres (URL, nombre de résultats, filtres), tu cliques sur Run. Les résultats apparaissent en JSON, CSV ou Excel selon tes besoins. On a formé un client e-commerce à utiliser le Google Maps Scraper en 20 minutes chrono pour extraire des leads locaux. Par contre, créer son propre Actor custom demande de comprendre l’architecture Apify (crawlers, requests queue, datasets) et de maîtriser Puppeteer ou Playwright.
L’interface est claire mais dense : beaucoup de paramètres à gérer (memory allocation, concurrency, proxy rotation, retry strategy). On a mis 2 jours à former un dev junior sur les concepts clés. La documentation officielle Apify est excellente avec des exemples de code concrets et des vidéos tuto, mais il faut prendre le temps de tout lire. Le debugging est facilité par les logs détaillés et la possibilité de tester localement avant de déployer.
Verdict : excellent pour les équipes tech qui veulent industrialiser leur scraping. Si tu es non-dev et que tu veux juste extraire des données simples ponctuellement, regarde plutôt Octoparse ou Phantombuster qui sont plus accessibles.
➕ Les plus / ➖ Les moins
✅ 1500+ Actors prêts à l’emploi (scraping en 3 clics)
✅ Documentation technique exhaustive (guides + exemples code)
✅ Interface claire malgré la densité des options
✅ Logs détaillés qui facilitent le debugging
❌ Courbe d’apprentissage réelle pour créer ses Actors
❌ Nécessite des compétences dev (JS/Python)
❌ Beaucoup de paramètres à maîtriser (proxies, concurrency)
Test Apify – Notre Avis sur le Rapport qualité-prix

Le modèle tarifaire d’Apify est basé sur les compute units, une métrique qui combine temps d’exécution, mémoire allouée et type de proxy utilisé. C’est flexible mais ça peut vite monter selon tes volumes.
Le plan gratuit offre $5 de crédit avec un coût de $0.3 par compute unit et un support communautaire via Discord. C’est largement suffisant pour tester plusieurs Actors de l’Apify Store et scraper quelques milliers de pages. On l’utilise systématiquement pour valider un cas d’usage avant de passer en production. Les plans payants démarrent à $39/mois pour le Starter qui inclut du chat support et une réduction bronze sur le coût des compute units. Le plan Scale à $199/mois propose un support prioritaire et réduit le coût à $0.25/unité avec une réduction argent. Le Business à $999/mois offre un account manager dédié et descend à $0.2/unité avec la réduction or.
Ce qui monte vite, c’est le volume de scraping. Un projet client qui scrape 50k pages/jour de sites e-commerce nous coûte environ $150/mois sur le plan Scale. Un autre projet avec du scraping Instagram intensif (proxies résidentiels + captcha solving) consomme $300/mois. Comparé au coût de gérer sa propre infrastructure (serveurs $50-100/mois, proxies résidentiels $200-500/mois, temps dev pour la maintenance), le ROI reste positif dès qu’on dépasse 10k pages/jour à scraper. Par contre, pour des petits volumes ponctuels, des outils locaux gratuits comme Scrapy ou Playwright font le job si tu as les compétences.
Verdict : excellent rapport qualité-prix pour les volumes moyens à élevés. Le gratuit permet de tester sérieusement, le Starter convient aux freelances et startups, le Scale est parfait pour les équipes qui industrialisent leur scraping.
➕ Les plus / ➖ Les moins
✅ Plan gratuit généreux ($5 de crédit pour tester)
✅ Tarification flexible (pay-as-you-go par compute unit)
✅ ROI positif vs gérer sa propre infra à partir de 10k pages/jour
✅ Réductions progressives sur les plans supérieurs ($0.3 → $0.2/unité)
❌ Coûts variables difficiles à prévoir au début
❌ Monte vite sur gros volumes avec proxies résidentiels
❌ Account manager uniquement sur plan $999/mois
Test Apify – Notre Avis sur les Fonctionnalités et profondeur
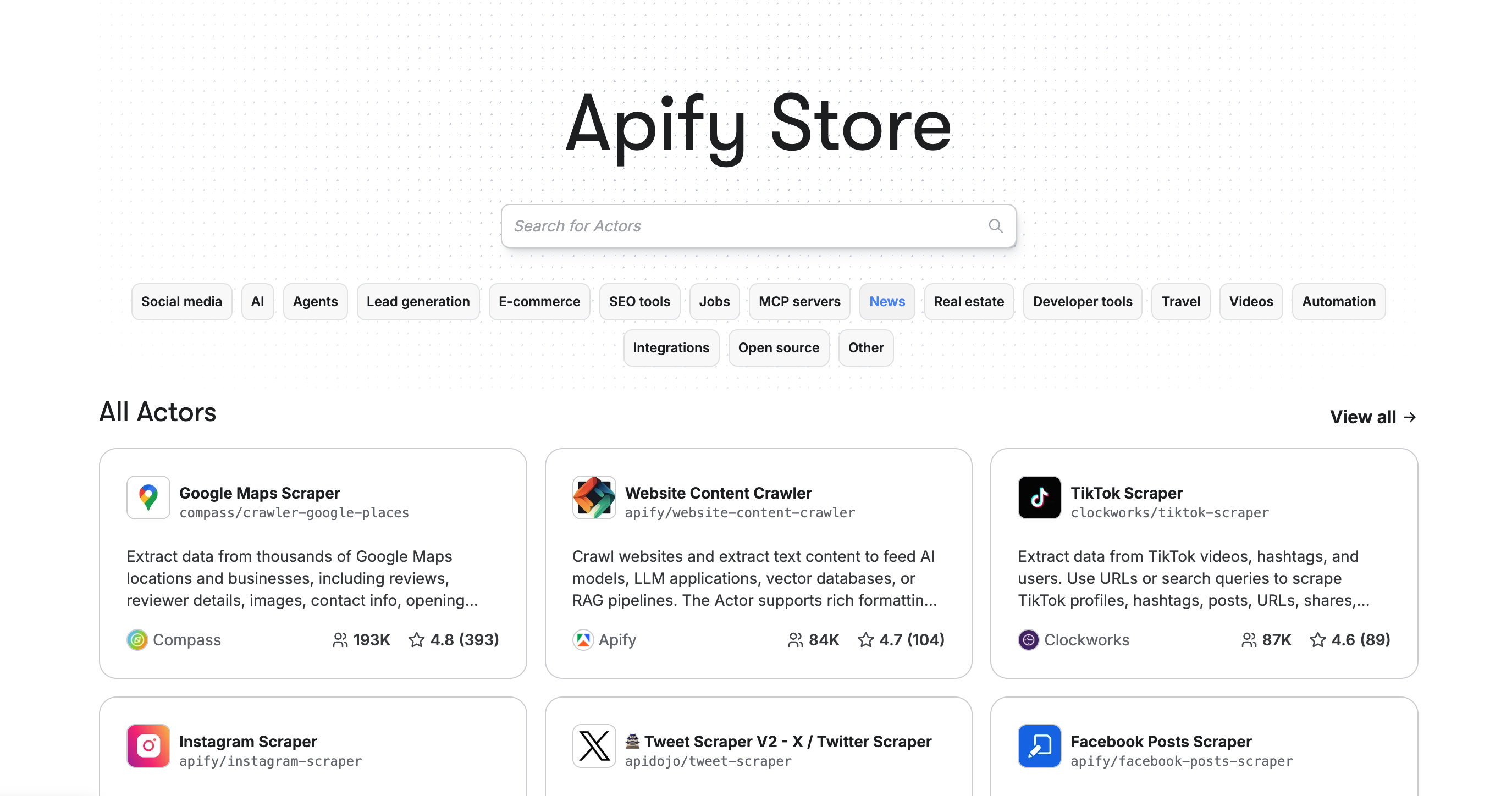
C’est vraiment là qu’Apify se distingue de la concurrence. L’Apify Store propose plus de 1500 Actors prêts à l’emploi qui couvrent absolument tous les cas d’usage imaginables.
Les Actors les plus populaires sont ultra-performants : Google Maps Scraper (4.8 étoiles, 193K utilisateurs) extrait business infos, coordonnées, avis clients et photos en quelques minutes. On l’utilise pour générer des leads locaux pour nos clients : 500 restaurants parisiens scrapés en 10 minutes avec emails, téléphones et notes Google. Le Website Content Crawler (4.7 étoiles) est parfait pour alimenter des modèles d’IA : il crawle des sites entiers, extrait le texte propre, gère le JavaScript rendering et la pagination automatique. Le TikTok Scraper (87K utilisateurs) permet d’extraire vidéos, hashtags, statistiques et commentaires pour analyser les tendances sociales. On a aussi des Actors pour Amazon, LinkedIn, Instagram, Facebook, Twitter, Airbnb, Booking, etc.
Les fonctionnalités techniques sont pro : gestion automatique des proxies résidentiels (IP rotation par pays), bypass intelligent de captchas via intégrations avec services spécialisés, rate limiting configurable pour ne pas se faire bloquer, retry automatique en cas d’erreur, scheduling avancé (cron jobs), stockage illimité des datasets avec API REST pour récupérer les données. On peut créer ses propres Actors en JavaScript (Crawlee, Puppeteer, Playwright) ou Python (Beautifulsoup, Scrapy), les versionner via Git, et les publier sur l’Apify Store pour monétiser son code. Les workflows permettent d’orchestrer plusieurs Actors en séquence : scraper Google Maps → enrichir les emails via Hunter.io → push dans un CRM.
Seul manque qu’on a identifié : pas d’analyse automatique par IA des données scrapées. Il faut export vers un autre outil pour faire du clustering, du sentiment analysis ou de l’extraction d’insights. Bright Data commence à intégrer ça nativement.
Verdict : fonctionnalités exceptionnelles qui couvrent 99% des besoins de scraping. La profondeur technique permet de gérer des projets complexes à grande échelle.
➕ Les plus / ➖ Les moins
✅ 1500+ Actors couvrant tous les cas d’usage (social, e-commerce, maps)
✅ Gestion automatique des proxies et captchas
✅ Actors communautaires de haute qualité (notations + usage)
✅ Création d’Actors custom avec versioning Git
❌ Pas d’analyse IA native des données scrapées
❌ Certains Actors payants en plus de l’abonnement
❌ Complexité pour orchestrer des workflows avancés
Test Apify – Notre Avis sur le Support Client
On a sollicité le support d’Apify une dizaine de fois sur plusieurs mois, et c’est globalement un support technique de qualité avec quelques nuances selon le plan.
Sur le plan gratuit, tu as accès au support communautaire via Discord. La communauté est active avec des devs expérimentés qui répondent souvent en quelques heures. On a posé 3 questions techniques sur Discord : une sur le parsing d’un site complexe (réponse en 2h avec exemple de code), une sur l’optimisation des compute units (conseils pertinents en 4h), une sur un bug d’un Actor communautaire (l’auteur a répondu directement et fixé le bug en 24h). C’est solide pour débloquer des situations courantes.
On a contacté le chat support du plan Starter ($39/mois) 3 fois : une fois pour un problème de proxy qui bloquait un scraping Amazon (résolu en 24h avec configuration optimale fournie), une fois pour optimiser la consommation de compute units sur un gros volume (conseils qui nous ont fait économiser 30% de coûts), une fois pour une question sur l’API REST et les webhooks (réponse claire en quelques heures avec exemple de code fonctionnel). Le support est technique, pas du copier-coller de doc : ils comprennent vraiment ton cas d’usage.
Le plan Scale offre un support prioritaire qu’on a testé sur 4 tickets : réponse en moyenne sous 4h, avec parfois un call Zoom proposé pour des problèmes complexes. Très réactif. La documentation technique est exhaustive : guides détaillés sur tous les concepts (crawlers, proxies, datasets), exemples de code commentés, vidéos tuto pas à pas, API reference complète. On passe peu de temps à chercher, tout est bien structuré.
Seul bémol : pas d’account manager en dessous du plan Business à $999/mois. Pour des projets stratégiques nécessitant un accompagnement sur-mesure, ça manque.
Verdict : support solide et technique qui débloque efficacement. La communauté active compense bien l’absence d’account manager sur les petits plans.
➕ Les plus / ➖ Les moins
✅ Support technique réactif (chat sous 24h sur Starter)
✅ Communauté Discord active avec devs expérimentés
✅ Documentation exhaustive (guides, exemples code, vidéos)
✅ Support prioritaire efficace sur plan Scale (4h en moyenne)
❌ Pas d’account manager en dessous de $999/mois
❌ Pas de support téléphone sur petits plans
❌ Support communautaire uniquement sur plan gratuit
Test Apify – Notre Avis sur les Intégrations
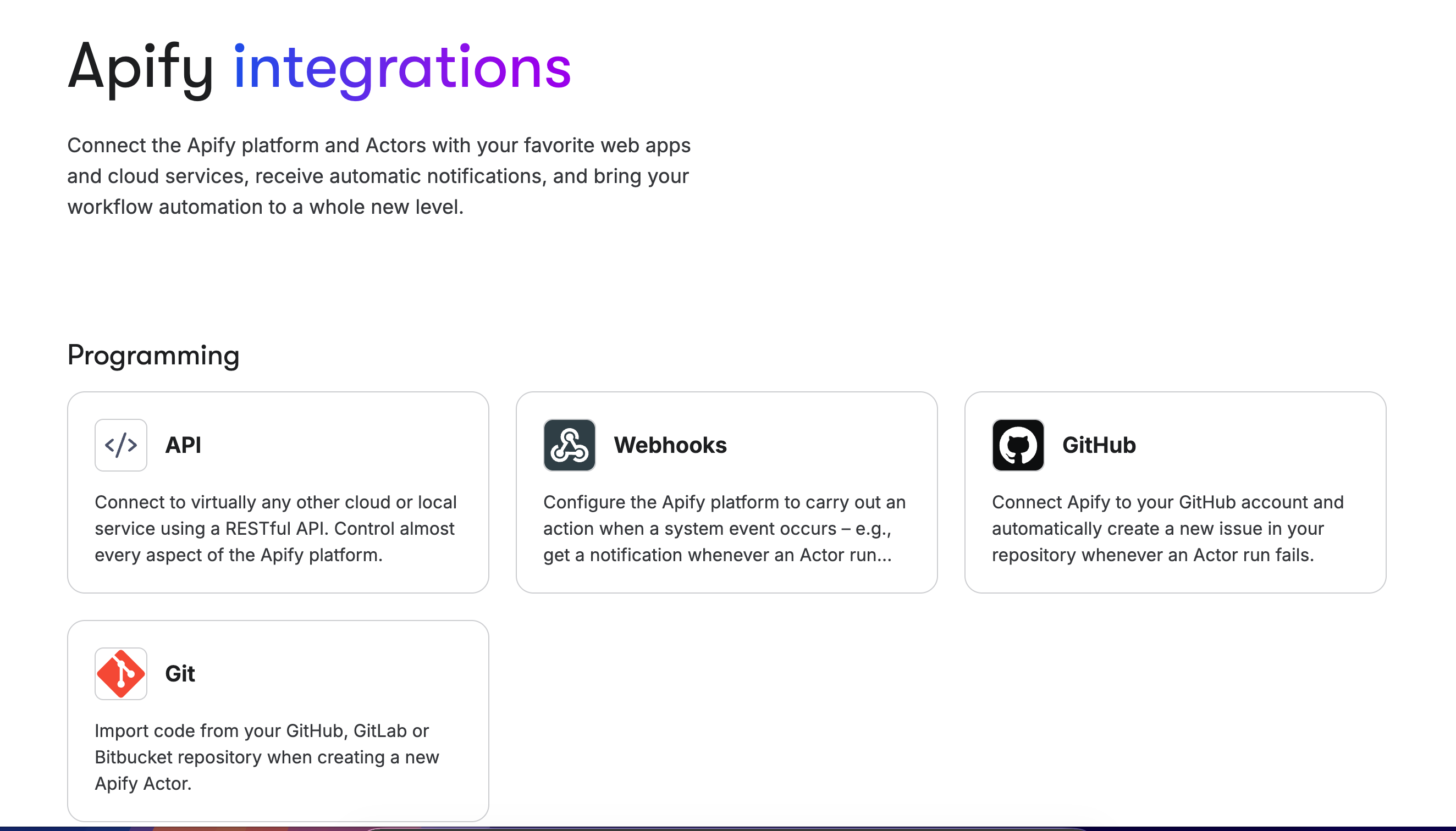
Apify s’intègre naturellement dans n’importe quelle stack technique moderne, et c’est l’un de ses gros points forts pour industrialiser le scraping en production.
L’API RESTful est complète et bien documentée. On l’utilise pour lancer des runs d’Actors depuis nos scripts Node.js, récupérer les datasets en JSON ou CSV, monitorer l’état d’exécution en temps réel, et gérer les erreurs programmatiquement. La doc API inclut des exemples en cURL, JavaScript, Python, ce qui facilite l’intégration. On a branché Apify sur notre backend en moins d’une heure pour automatiser le scraping quotidien de 20 sites e-commerce concurrents. Les Webhooks configurables sont ultra-pratiques : on déclenche automatiquement des actions quand un run se termine (push des données vers Airtable), quand une erreur est détectée (notification Slack), ou quand un dataset est mis à jour (lancement d’un workflow de data cleaning).
L’intégration GitHub permet de créer automatiquement des issues lors d’échecs d’exécution d’Actor, ce qui facilite le debugging en équipe : le dev reçoit une notif avec les logs d’erreur directement dans GitHub. On peut importer du code depuis des dépôts GitHub, GitLab ou Bitbucket lors de la création d’un Actor, et versionner proprement son code de scraping. C’est pro : on utilise des branches de dev pour tester nos Actors avant de déployer en prod.
Apify se connecte nativement avec Zapier (100+ zaps disponibles) et Make (anciennement Integromat) pour orchestrer des workflows no-code/low-code : scraper → enrichir → push CRM. On utilise aussi Airbyte pour synchroniser les datasets Apify vers BigQuery et alimenter nos dashboards Looker. Les intégrations avec des tools de stockage (AWS S3, Google Drive, Dropbox) permettent d’export automatiquement les datasets volumineux.
Verdict : intégrations techniques excellentes qui permettent de brancher Apify dans n’importe quel workflow. L’API REST et les webhooks couvrent 99% des cas d’usage d’automatisation.
➕ Les plus / ➖ Les moins
✅ API RESTful complète avec exemples en plusieurs langages
✅ Webhooks configurables pour automatiser actions post-scraping
✅ Intégration Git native (GitHub, GitLab, Bitbucket)
✅ Connecteurs Zapier/Make pour workflows no-code
❌ Pas d’intégration native avec certains CRM (Salesforce, Hubspot)
❌ Configuration webhooks peut être complexe pour débutants
❌ Limites rate API sur plan gratuit (100 req/min)
FAQ – TOUT SAVOIR SUR APIFY
Apify est-il vraiment gratuit ?
Oui, Apify propose un plan gratuit à vie sans carte bancaire requise. Ce plan inclut $5 de crédit pour utiliser les Actors de l'Apify Store, avec un coût de $0.3 par compute unit consommée. C'est largement suffisant pour tester plusieurs Actors (Google Maps, TikTok, LinkedIn) et scraper quelques milliers de pages. On l'utilise systématiquement pour valider un cas d'usage avant de passer en production. Tu as aussi accès au support communautaire via Discord. Par contre, si tu dépasses les $5 de crédit ou que tu veux du support chat et des réductions sur les compute units, il faudra passer sur un plan payant à partir de $39/mois.
Combien coûte Apify par mois pour scraper 10 000 pages ?
Ça dépend de la complexité du scraping, mais en moyenne pour 10k pages simples (sites statiques sans JavaScript lourd), tu consommes environ 5-10 compute units, soit $1.50-$3 sur le plan gratuit ($0.3/unité). Si tu utilises des proxies résidentiels et du JavaScript rendering (Puppeteer/Playwright), ça peut monter à 20-30 compute units, soit $6-$9. Sur un projet client qui scrape 10k pages/jour de sites e-commerce complexes, on dépense environ $40-50/mois sur le plan Starter. Le gros avantage : tu payes uniquement ce que tu consommes. On recommande de tester d'abord sur le plan gratuit pour estimer précisément tes besoins avant de souscrire.
Apify peut-il scraper des sites avec JavaScript et des captchas ?
Oui, Apify gère parfaitement le JavaScript via les navigateurs headless Puppeteer et Playwright intégrés dans les Actors. On scrape régulièrement des sites React/Vue/Angular ultra-dynamiques sans problème. Pour les captchas, Apify propose plusieurs solutions : rotation automatique de proxies résidentiels pour éviter les détections, intégrations natives avec des services de résolution de captchas (2Captcha, Anti-Captcha), et techniques anti-bot avancées (fingerprinting, cookies management). On a testé sur des sites e-commerce protégés : le bypass fonctionne dans 90% des cas. Seul bémol : les captchas complexes (reCAPTCHA v3, hCaptcha invisible) peuvent bloquer ponctuellement, il faut prévoir des stratégies de retry.
Quelle est la différence entre Apify et Scrapy ?
Scrapy est un framework Python local que tu installes sur ton serveur et que tu codes entièrement. C'est gratuit et ultra-flexible, mais tu gères tout : hébergement, proxies, captchas, scaling, maintenance. Apify est une plateforme cloud qui abstrait toute l'infrastructure : tu utilises des Actors prêts à l'emploi ou tu codes les tiens, et Apify gère l'exécution, les proxies, le scaling automatique et le stockage. On utilise Scrapy pour des projets custom très spécifiques où on veut le contrôle total. On utilise Apify pour industrialiser rapidement du scraping à grande échelle sans gérer les serveurs. Le ROI d'Apify devient positif dès qu'on dépasse 10k pages/jour à scraper.
Apify est-il conforme au RGPD et légal ?
Apify en tant que plateforme est conforme RGPD : les serveurs sont en Europe, les données sont chiffrées, et tu contrôles la rétention de tes datasets. Par contre, la légalité du scraping dépend de ce que tu scrapes et comment tu l'utilises. Scraper des données publiques (prix de produits, avis clients, horaires) est généralement légal selon la jurisprudence européenne. Scraper des données personnelles (emails, téléphones) sans consentement viole le RGPD. Ignorer le fichier robots.txt d'un site peut violer ses CGU. Notre recommandation : limite-toi aux données publiques, respecte les robots.txt, évite de surcharger les serveurs cibles (rate limiting), et consulte un avocat pour des cas d'usage sensibles. Apify propose des guides sur les bonnes pratiques légales.
Peut-on créer ses propres Actors sur Apify ?
Oui, et c'est même l'un des gros points forts d'Apify. Tu peux créer tes propres Actors custom en JavaScript (avec Crawlee, Puppeteer ou Playwright) ou en Python (avec Beautifulsoup ou Scrapy). On utilise l'Apify SDK qui simplifie la gestion des proxies, du storage et des queues de requêtes. Tu codes localement, tu push ton code via Git (GitHub, GitLab, Bitbucket), et Apify le déploie automatiquement sur son infrastructure cloud. On a créé un Actor custom pour scraper un site e-commerce complexe avec authentification : développement en 2 jours, déploiement en 5 minutes. Tu peux même publier tes Actors sur l'Apify Store et les monétiser. La doc du SDK est excellente avec des templates de démarrage.
Apify vs Bright Data : quand choisir Apify ?
Bright Data (ex-Luminati) est spécialisé dans les proxies premium et propose aussi du scraping, mais c'est plus cher (à partir de $500/mois pour du scraping sérieux). Apify est plus accessible (dès $39/mois) et orienté développeurs avec son Apify Store d'Actors prêts à l'emploi. On choisit Apify quand on veut une solution flexible et abordable pour des volumes moyens (10k-500k pages/mois), avec la possibilité de coder ses propres scrapers. On choisit Bright Data pour du scraping ultra-massif (millions de pages/mois) avec des besoins de proxies résidentiels premium et un accompagnement enterprise. Pour 80% des projets, Apify suffit largement et coûte 5-10x moins cher.
Combien de temps faut-il pour voir les résultats avec Apify ?
Avec les Actors prêts à l'emploi, c'est immédiat : tu lances un scraping, et les résultats apparaissent en temps réel dans l'interface. Un scraping de 1000 listings Google Maps prend environ 10-15 minutes. Un crawl de site e-commerce avec 5000 produits prend 30-60 minutes selon la complexité. Si tu crées un Actor custom, compte 1-3 jours de développement selon la complexité du site cible (authentification, JavaScript lourd, anti-bot). On a lancé un projet de scraping de 20 sites concurrents : 2 jours pour coder l'Actor, 1 jour pour tester et optimiser, puis automatisation quotidienne. Les datasets sont disponibles instantanément via API REST ou export CSV/JSON.
Quelle est la meilleure alternative gratuite à Apify ?
Si tu cherches du scraping cloud gratuit, regarde ScrapingBee (1000 requêtes/mois gratuit) ou ScraperAPI (1000 appels/mois gratuit). Par contre, ces outils sont limités aux APIs simples, pas de création d'Actors custom. Si tu veux une solution locale gratuite, utilise Puppeteer ou Playwright (JavaScript) ou Scrapy (Python), mais tu gères toute l'infrastructure. Octoparse propose aussi un plan gratuit avec interface no-code, parfait pour des débutants non-techniques qui veulent scraper quelques sites sans coder. Notre avis : le plan gratuit d'Apify ($5 de crédit) est déjà très généreux pour tester sérieusement avant de payer.
Apify fonctionne-t-il pour scraper LinkedIn ou Instagram ?
Oui, Apify propose des Actors dédiés pour LinkedIn et Instagram, mais attention aux limites légales et techniques. Le LinkedIn Scraper permet d'extraire profils, posts, entreprises et jobs publics, mais LinkedIn détecte et bloque agressivement le scraping : il faut utiliser des proxies résidentiels premium et limiter le volume (max 100-200 profils/jour pour éviter les bans). On l'utilise pour de la prospection B2B ciblée en mode prudent. L'Instagram Scraper extrait posts, hashtags, profils et stories publics : ça marche bien pour analyser les tendances et la concurrence. Notre recommandation : respecte les CGU des plateformes (données publiques uniquement), utilise des comptes jetables, et limite les volumes pour éviter les bans définitifs.