Agent IA pour extraire automatiquement les infos d’un CV (via n8n)
Tu veux extraire automatiquement les informations d’un CV sans passer des heures à tout recopier ? Cette automatisation n8n te fait gagner un temps précieux grâce à un agent IA qui structure les données pour toi.
L'automatisation complète, dans ta boîte
Agent IA pour extraire automatiquement les infos d’un CV (via n8n)

Extraire Automatiquement les Infos Clés d'un CV avec un Agent IA (Workflow n8n Gratuit + Vidéo + Tutoriel + Téléchargement)
Pré-requis : Avoir une Instance n8n Self-Hosted avec Accès au Terminal
! Il te fautPré-requis : Avoir une Instance n8n Self-Hosted avec Accès au Terminal
- A self-hosted n8n instance with terminal access.
- API credentials for the services used in this workflow.
L'automatisation complète, dans ta boîte
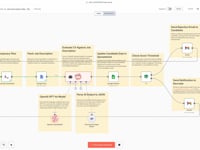
Détail du workflow n8n.
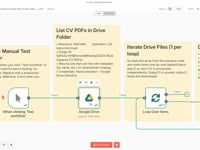
01 Étape 01Lancer le Workflow (Manual Trigger).
Cette première étape te permet de tester le workflow manuellement. Grâce au module Manual Trigger de n8n, tu peux lancer le scénario à la demande pour vérifier son bon fonctionnement avant de l'automatiser en production.
Le déclencheur manuel est très utile pour tester chaque étape en temps réel et diagnostiquer facilement les éventuelles erreurs. Une fois tes tests validés, tu pourras remplacer ce déclencheur par un trigger automatisé (ex : cron, webhook…) si besoin.
Pour démarrer : clique sur "Exécuter le workflow" dans n8n pour initier le traitement.
Paramètres- Type de déclencheur : Manual Trigger
- Utilisation : Lancement manuel du workflow via l'interface n8n
02 Étape 02Récupérer la Liste des CV depuis Google Drive.
Cette étape permet de lister automatiquement tous les fichiers PDF présents dans un dossier spécifique de ton Google Drive. Chaque fichier correspond à un CV qui sera ensuite traité individuellement par l'agent IA.
💡 Astuce : tu peux récupérer l'ID de ton dossier Drive dans l'URL lorsque tu es à l'intérieur du dossier. C'est la partie après
/folders/.Paramètres- Module : Google Drive
- Opération : Lister tous les fichiers dans un dossier
- Dossier : ID de ton dossier Google Drive contenant les CV
- Authentification : Ton propre compte Google connecté à n8n
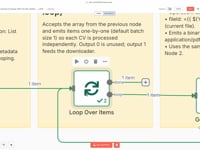
03 Étape 03Traiter les CV un par un (Loop).
Cette étape utilise le module Split In Batches pour traiter chaque CV de manière indépendante. On boucle ainsi sur chaque fichier PDF récupéré, afin de l'exécuter dans un flux isolé.
Cela garantit un traitement propre et évite toute confusion si plusieurs fichiers sont présents dans le dossier.
Paramètres- Batch Size : 1 (pour traiter un seul fichier à la fois)
- Sortie utilisée : Sortie 1 (vers le téléchargement)
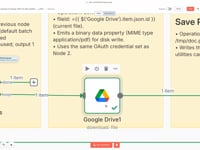
04 Étape 04Télécharger le CV depuis Google Drive.
Cette action télécharge le fichier PDF du CV depuis ton dossier Google Drive, en utilisant l'ID du fichier récupéré dans la boucle.
💡 Tu peux aussi remplacer cette source par un déclencheur Gmail, une API ou tout autre système d'arrivée de CV.
Paramètres- Module : Google Drive
- Opération : Télécharger un fichier
- Fichier : ID dynamique du fichier (provenant du loop)
- Authentification : Ton propre compte connecté à n8n
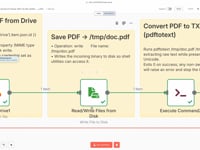
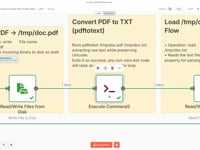
05 Étape 05Enregistrer le PDF localement.
On enregistre le fichier PDF sur le serveur dans un chemin temporaire (
/tmp/doc.pdf) afin de pouvoir l'utiliser avec une commande d'extraction de texte.Paramètres- Fichier : /tmp/doc.pdf
- Contenu : Données binaires du PDF téléchargé
06 Étape 06Extraire le Texte du CV (PDFtoText).
On utilise ici la commande
pdftotext(fournie par Poppler) pour transformer le PDF en un fichier texte lisible par l'agent IA. Cette commande doit être installée sur ton serveur.➡️ Commande exécutée :
pdftotext /tmp/doc.pdf /tmp/doc.txt💡 Si tu ne sais pas comment installer cette commande, demande à ChatGPT selon ton système (Linux, Docker, Mac…) ou contacte-nous.
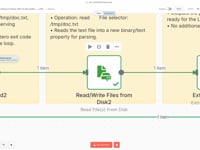
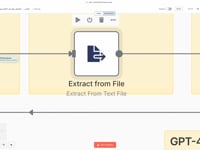
07 Étape 07Lire le Contenu du Fichier Texte.
On lit le fichier
/tmp/doc.txtgénéré parpdftotext. Le contenu est chargé dans n8n pour être transmis à l'agent IA dans l'étape suivante.08 Étape 08Préparer le Texte pour l'Analyse.
Cette étape nettoie et structure le contenu texte brut pour qu'il soit proprement analysé par l'agent IA. Le texte est ensuite disponible dans
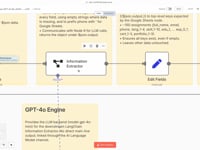
$json.data.09 Étape 09Analyser le CV avec un Agent IA (GPT-4o).
Le contenu texte est envoyé à un agent IA basé sur GPT-4o via LangChain. Il extrait toutes les informations importantes du CV (nom, mail, expériences, compétences, etc.).
➡️ Prompt : structure fixe, noms de colonnes prédéfinis, apostrophe ajoutée aux numéros pour compatibilité Google Sheets.
10 Étape 10Structurer les Données à Plat.
On transforme le JSON retourné par l'agent IA en une structure à plat, compatible avec l'import automatique dans Google Sheets. Chaque propriété (ex :
lang_1,edu_1_degree) est explicitement mappée.💡 Si tu veux envoyer les données ailleurs (Notion, Airtable, base SQL…), tu peux adapter ce bloc.
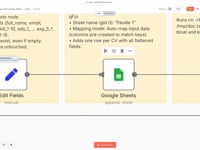
11 Étape 11Ajouter les Données Structurées dans un Google Sheets.
Les informations extraites sont ajoutées automatiquement dans une nouvelle ligne de ton Google Sheet. Chaque colonne correspond à un champ bien défini du CV.
➡️ Connexion : Google Sheets connecté à ton compte
💡 Tu peux aussi modifier cette étape pour envoyer les données dans Notion, Airtable ou n'importe quelle base.
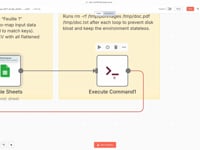
12 Étape 12Nettoyer le Serveur.
Cette commande supprime tous les fichiers temporaires (
/tmp/doc.pdfet/tmp/doc.txt) après chaque boucle pour garder un environnement propre.➡️ Commande :
rm -rf /tmp/doc.pdf /tmp/doc.txt

Récupère le JSON n8n prêt à importer + le guide
Laisse ton email et on t'envoie le scénario complet.
- JSON n8n prêt à importer
- Guide de setup écrit
- Tuto vidéo inclus
Pourquoi Extraire Automatiquement les Infos d'un CV est Essentiel pour Ton Process de Recrutement
Gérer efficacement des Candidatures ou Profils dans ton CRM ou ATS est essentiel pour automatiser ton process de recrutement et éviter les pertes d'informations. Analyser manuellement des CV en PDF prend du temps, ralentit les prises de décision, et introduit des erreurs humaines. Problèmes liés à l'extraction manuelle : Informations manquantes ou mal saisies (emails, expériences, langues…). Temps perdu à copier-coller chaque CV dans un fichier ou une base. Difficulté à trier ou filtrer efficacement les profils selon des critères précis. Retards dans le traitement des candidatures et opportunités manquées. Les avantages d'extraire automatiquement les données des CV : Structuration propre et normalisée de tous les profils reçus. Gain de temps énorme sur le tri et la qualification des candidats. Automatisation fluide avec Google Sheets, Notion, Airtable, ou ton CRM. Possibilité de déclencher des actions personnalisées (envoi d'email, scoring, tagging…). En automatisant l'extraction des informations depuis des CV PDF avec un agent IA, tu élimines les tâches chronophages, tu fiabilises tes données, et tu gagnes en réactivité. Ce scénario n8n devient un atout stratégique pour scaler ton processus de recrutement sans effort.
L'automatisation complète, dans ta boîte.
JSON n8n, guide écrit et tuto vidéo, tout pour déployer en moins de 15 minutes.
- Scénario n8n JSON complet
- Documentation de setup pas à pas
- Tuto vidéo complet